Local Beam Search

The great thing about the local search algorithms we've covered so far—from random walk, to gradient descent and hill climbing, and their variants—is that their memory footprint is small. They only need to store the current state and the best state they've found so far, so the memory usage is . But the more memory we give an agent, the more it can explore, and the more likely it is to find a global minimum or maximum. Local beam search is a generalization of gradient descent and hill climbing that keeps track of states simultaneously, rather than just one.
Local Beam Search
Lets return to our running example of optimizing the locations of fire stations in a city. We'll use local beam search to place the fire stations such that the total distance of each home to its nearest fire station is minimized.
Local beam search works by randomly picking initial states. Lets say for our example.
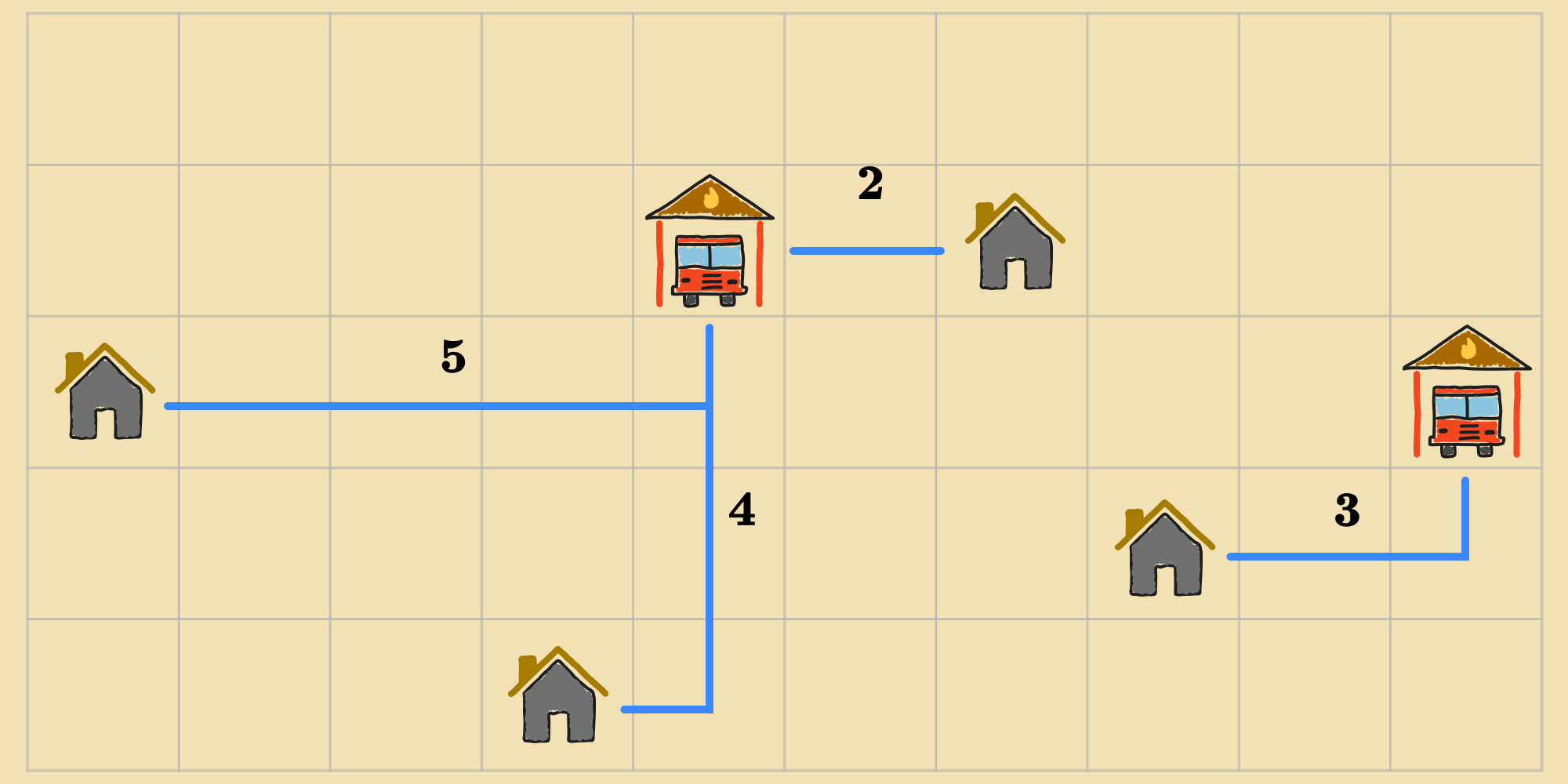
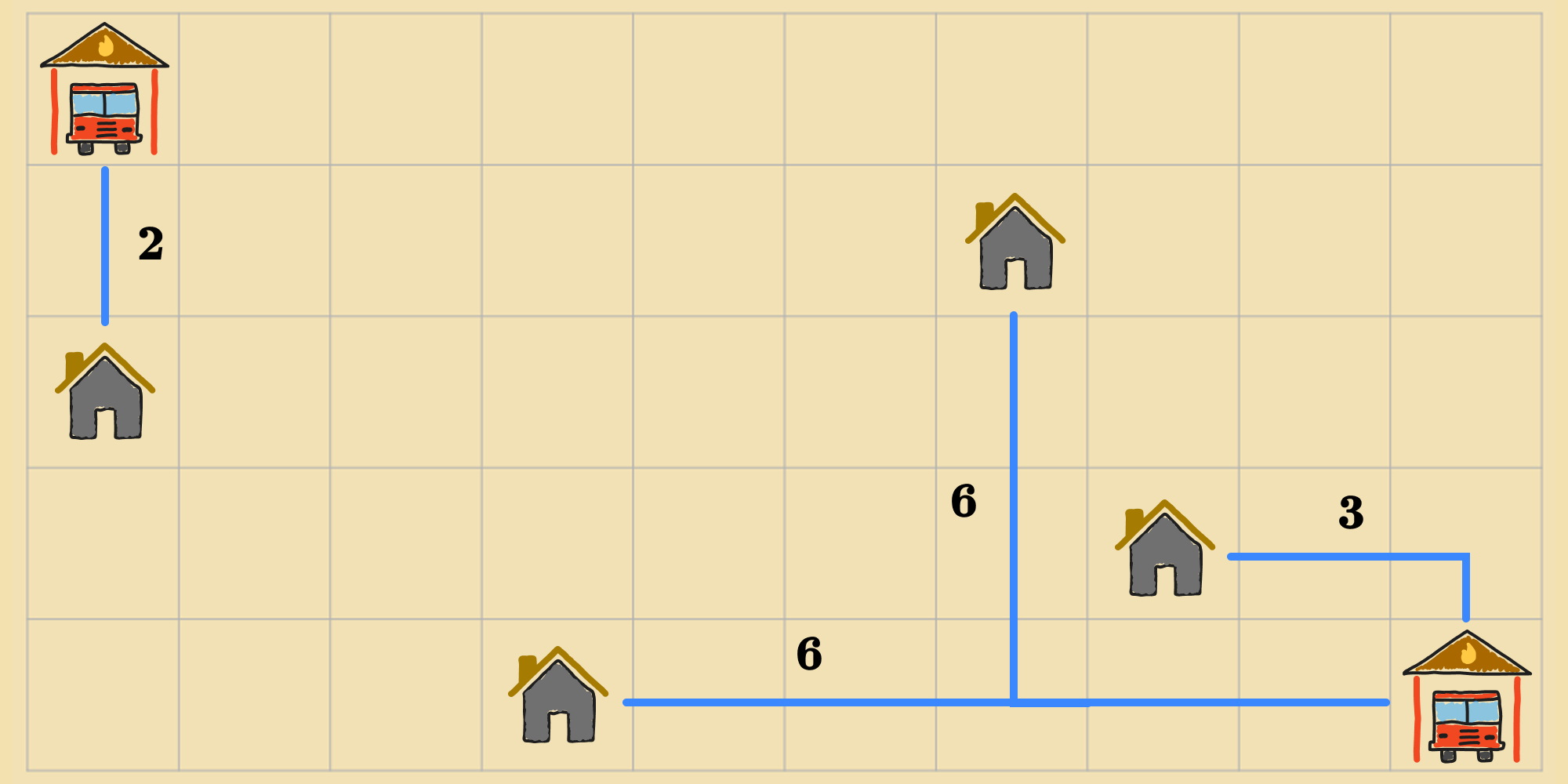
At each step, all the successors of all states are generated. This is just like how previous algorithms would find the successors of the agent's current state during each iteration. From this set of successors, the agent selects the best states, according to the objective function (if there's a tie amongst more than states, the agent randomly chooses of them).
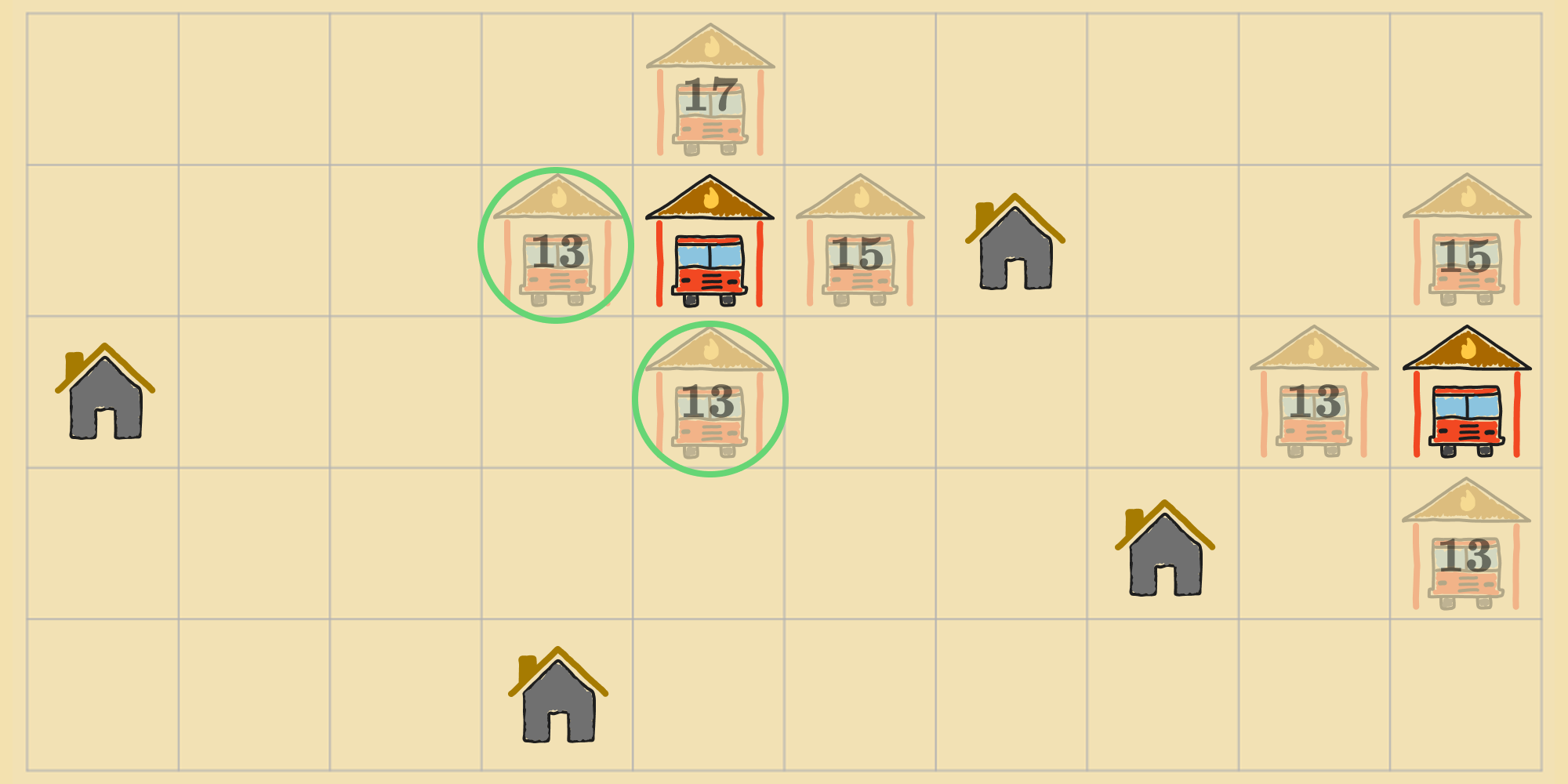
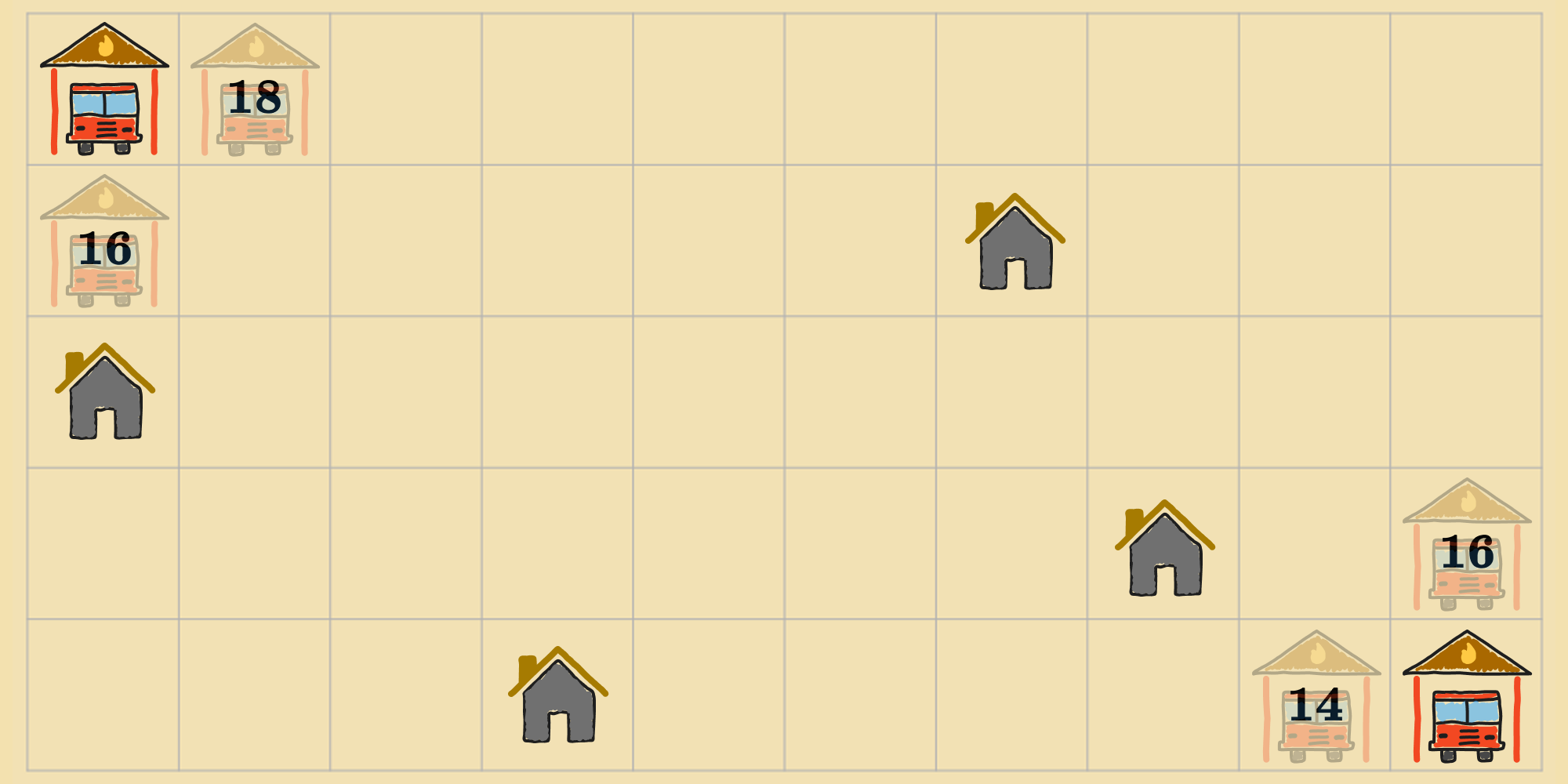
Then, the agent transitions to the top neighbors.

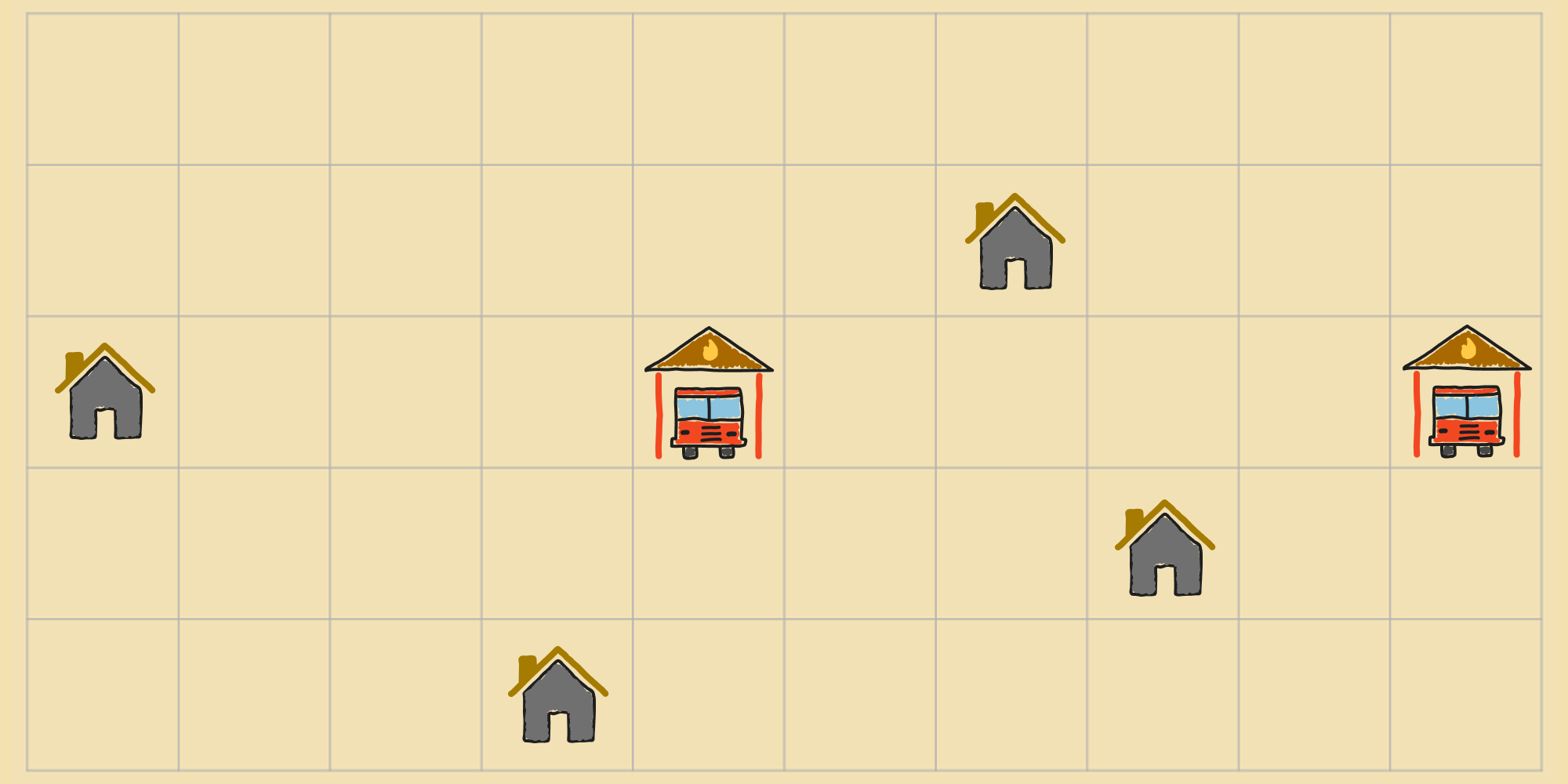
This process repeats until the agent can no longer improve the states its tracking. Again, this is analogous to how previous algorithms functioned, except that we're applying steps to multiple states simultaneously instead of just one. Here's the version of the local beam search algorithm tailored for objective minimization:
The variant for objective maximization is exactly the same, except that we replace the with a .
Local Beam Search vs Random Restart
At first glance, local beam search seems like its doing nothing more than running random-restarts in parallel instead of in order. But the two algorithms are quite different if you look closely. In random-restart, each search process runs independently of the others but in local beam search, useful information is passed among the states, , during each iteration. If , an agent running random-restart would pluck the best state from and the best state from for the next round of search. On the contrary, an agent running local beam search would choose the best states from . This gives the agent the ability to abandon some searches in favor of more promising regions where more progress is being made.
Stochastic Beam Search
The greediness of local beam search can lead to a lack of diversity among the states. If the states are clustered in a narrow region of the state space, the search reduces to a -times-slower version of gradient descent or hill climbing. Stochastic beam search, analogous to stochastic gradient descent, helps address this problem. Instead of choosing the top successors every time, stochastic beam search chooses successors with probability proportional to the successor's value, thus preserving some diversity.